if you are redlining the LLM, you aren't headlining

It’s an old joke in the DJ community about upcoming artists having a bad reputation for pushing the audio signal into the red. Red is bad because it results in the audio signal being clipped and the mix sounding muddy.

It’s a good analogy that applies to software engineers in the future, however, as these LLMs have context windows.
Claude 3.7’s advertised context window is 200k, but I've noticed that the quality of output clips at the 147k-152k mark. Regardless of which agent is used, when clipping occurs, tool call to tool call invocation starts to fail like below when using Claude 3.7:
≡ prompt
commit the changes and push
≡ Thinking
I don't have direct access to execute git commands on your system. To commit and push the changes, you'll need to run the following commands in your terminal:
# Add all modified files
git add .
# Commit with a descriptive message
git commit -m "Fix channel implementation and parser error reporting
- Fixed parser implementations for while statements and
- Enhanced error reporting in the parser with better con
- Fixed non-blocking channel operations tests
- Updated channel tests to verify implementation complet"
# Push to your remote repository
git push
These commands will:
1. Stage all the changes we made
2. Create a commit with a descriptive message
3. Push the changes to your remote repositoryAfter consulting with some mates in the field, I learned that "advertised" vs. "real" size is a thing—see this paper and the GitHub repository below.
Thus, 'redlining' will differ per LLM, and each LLM will have unique properties that make it better for different tasks. Some are better for generating the initial specifications, while others are better for implementing tasks within the specification. Either way, you must ensure that the evaluation loop you dispatch does not redline the LLM context window.
If I hadn't ditched Cursor, I would have never learned this observation, as they currently do not surface this information within their product. These days, I'm running raw directly to the Anthropic API. It's expensive, but the outcomes are dramatically better.
There's something cooked about Windsurf/Cursors' go-to-market pricing - there's no way they are turning a profit at $50/month. $50/month gets you a happy meal experience. If you want more power, you gotta ditch snacking at McDonald’s.
Going forward, companies should budget $100 USD to $500 USD per day, per dev, on tokens as the new normal for business, which is circa $25k USD (low end) to $50k USD (likely) to $127k USD (highest) per year.
If you don’t have OPEX per dev to do that, it’s time to start making some adjustments...
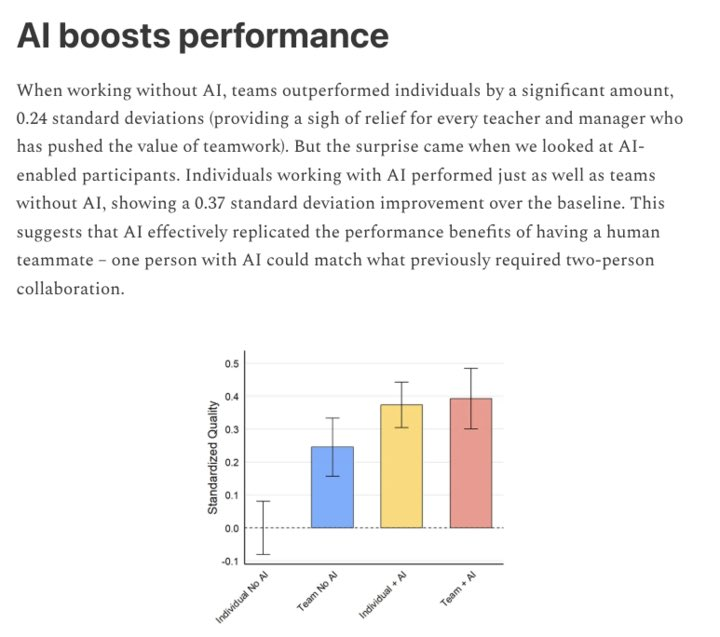
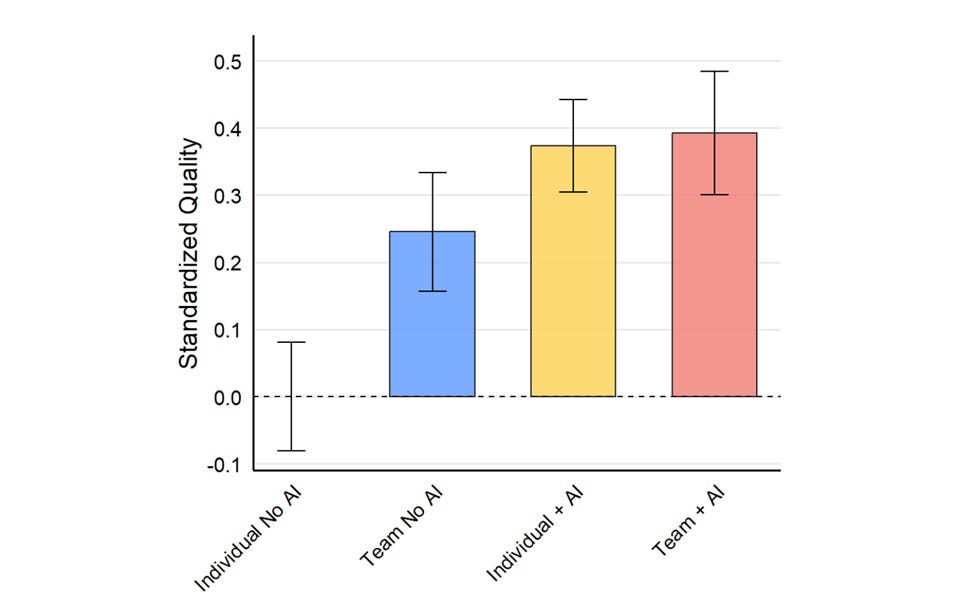
These tools make each engineer within your team at least two times more productive. Don't take my word for it—here's a study by Harvard Business School published last week that confirms this.
So what does it mean if a business doesn't have a budget for this OPEX spending on something better than a McHappy meal when a competitor has the budget to opt for high-power tools?
It means the budget will come from somewhere. If we take what we know—an engineering manager can only manage seven people—a team of switched-on engineers utilising these tools can output N-times more business outcomes than a team without them.
Suddenly, you need fewer teams and fewer engineering managers to get the same outcomes...