autoregressive queens of failure

Have you ever had your AI coding assistant suggest something so off-base that you wonder if it’s trolling you? Welcome to the world of autoregressive failure.
LLMs, the brains behind these assistants, are great at predicting the next word—or line of code—based on what's been fed into them. But when the context gets too complex or concerns within the context are mixed, they lose the thread and spiral into hilariously (or frustratingly) wrong territory. Let’s dive into why this happens and how to stop it from happening.
First, I'll need you to stop by the following blog post to understand an agent from first principles.

Still reading? Great. In the diagram below, an agent has been configured with two tools. Each tool has also been configured with a tool prompt, which advertises how to use the tool to the LLM.
The tools are:
- Tool 1 - Visit a website and extract the contents of the page.
- Tool 2 - Perform a Google search and return search results.
Now, imagine for a moment that this agent is an interactive console application that you use to search Google or visit a URL.
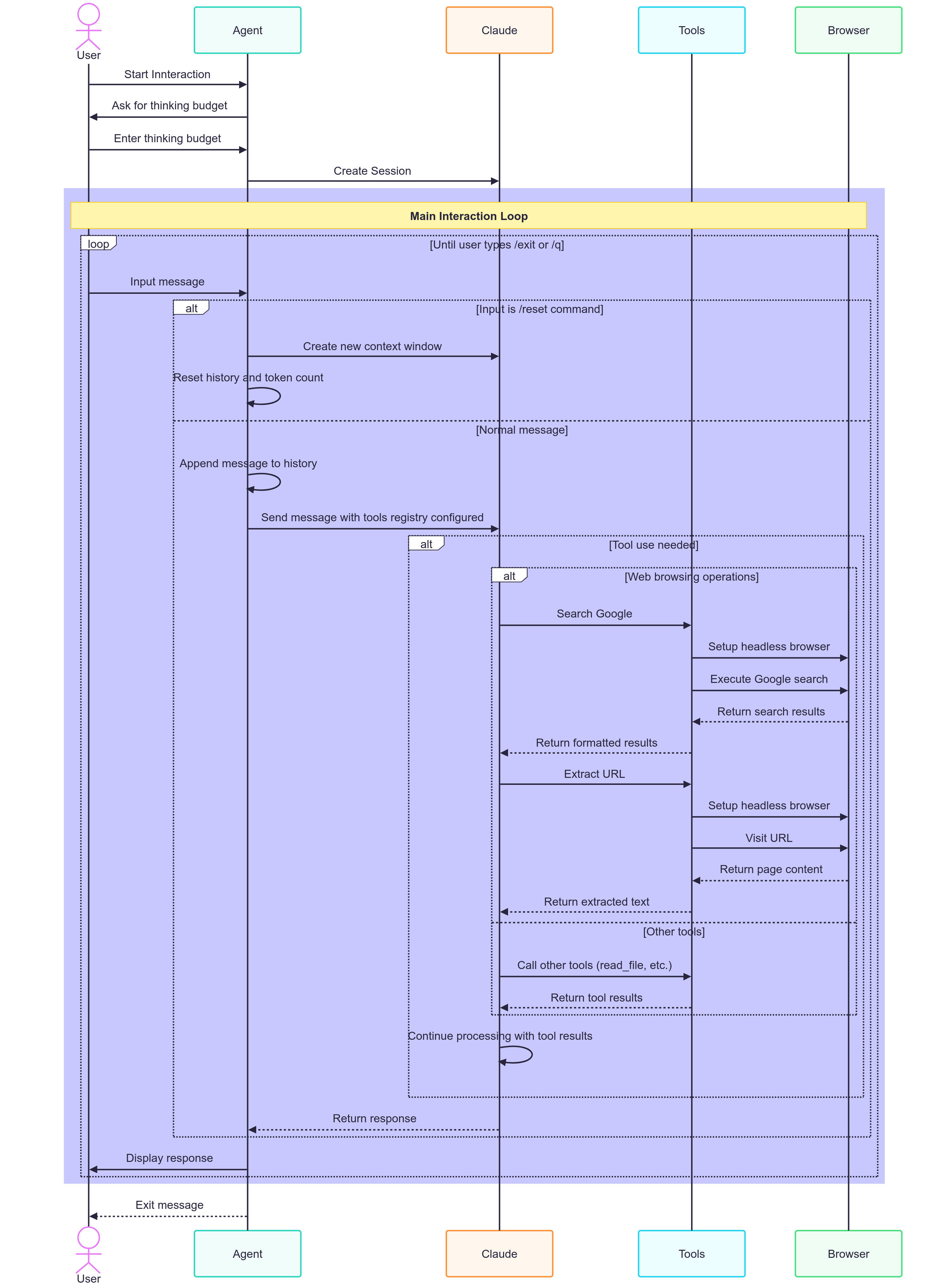
Whilst using the agent, you perform the actions:
- Visit a news website.
- Search Google for party hats.
- Visit a Wikipedia article about Meerkats.
Each of these operations allocates the results from the above operations into memory - the LLM context window.
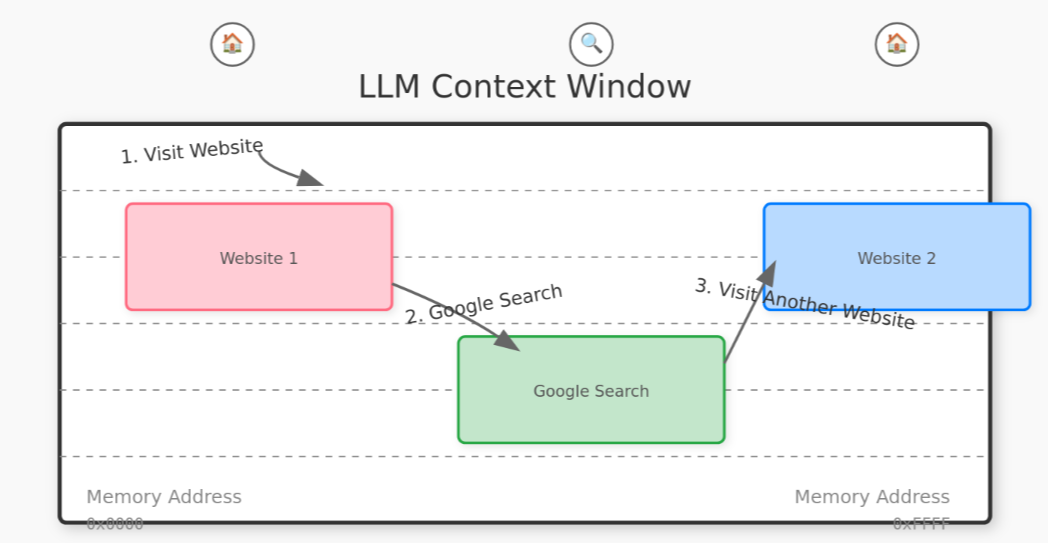
malloc()'ed into the LLM's context window. It cannot be free() 'd unless you create a brand new context window. With all that context loaded into the window, all that data is now available for consideration when you ask a question. Thus, there's a probability that it'll generate a news article about Meerkats wearing party hats in response to a search for Meerkat facts (ie. Wikipedia).
That might sound obvious, but it's not. The tooling that most software developers use day-to-day hides context windows from the user and encourages endless chatops sessions within the same context window, even if the current task is unrelated to the previous task.
This creates bad outcomes because what is loaded into memory is unrelated to the job to be done, and results in noise from software engineers saying that 'AI doesn't work', but in reality, it's how the software engineers are holding/using the tool that's at fault.
My #1 recommendation for people these days is to use a context window for one task, and one task only. If your coding agent is misbehaving, it's time to create a new context window. If the bowling ball is in the gutter, there's no saving it. It's in the gutter.
My #2 recommendation is not to redline the context window (see below)

ps. socials