how to build a coding agent: free workshop

Hey everyone, I'm here today to teach you how to build a coding agent. By this stage of the conference, you may be tired of hearing the word "agent".
You hear the word frequently. However, it appears that everyone is using this term loosely without a clear understanding of what it means or how these coding agents operate internally. It's time to pull back the hood and show that there is no moat.
Learning how to build a coding agent is one of the best things you can do for your personal development in 2025, as it teaches you the fundamentals. Once you understand these fundamentals, you'll move from being a consumer of AI to a producer of AI who can automate things with AI.
Let me open with the following facts:





With LLM tokens, that's all it is.
300 lines of code running in a loop with LLM tokens. You just keep throwing tokens at the loop, and then you've got yourself an agent.

Today, we're going to build one. We're going to do it live, and I'll explain the fundamentals of how it all works. As we are now in 2025, it has become the norm to work concurrently with AI assistance. So, what better way to demonstrate the point of this talk than to have an agent build me an agent whilst I deliver this talk?
Cool. We're now building an agent. This is one of the things that's changing in our industry, because work can be done concurrently and whilst you are away from your computer.
The days of spending a week or a couple of days on a research spike are now over because you can turn an idea into execution just by speaking to your computer.
The next time you're on a Zoom call, consider that you could've had an agent building the work that you're planning to do during that Zoom call. If that's not the norm for you, and it is for your coworkers, then you're naturally not going to get ahead.






The tech industry is almost like a conveyor belt - we always need to be learning new things.
If I were to ask you what a primary key is, you should know what a primary key is. That's been the norm for a long time.
In 2024, it is essential to understand what a primary key is.
In 2025, you should be familiar with what a primary key is and how to create an agent, as knowing what this loop is and how to build an agent is now fundamental knowledge that employers are looking for in candidates before they'll let you in the door.

As this knowledge will transform you from being a consumer of AI to being a producer of AI that can orchestrate your job function. Employers are now seeking individuals who can automate tasks within their organisation.
If you're joining me later this afternoon for the conference closing (see below), I'll delve a bit deeper into the above.

the conference closing talk

Right now, you'll be somewhere on the journey above.
On the top left, we've got 'prove it to me, it's not real,' 'prove it to me, show me outcomes', 'prove it to me that it's not hype', and a bunch of 'it's not good enough' folks who get stuck up there on that left side of the cliff, completely ignoring that there are people on the other side of the cliff, completely automating their job function.
In my opinion, any disruption or job loss related to AI is not a result of AI itself, but rather a consequence of a lack of personal development and self-investment. If your coworkers are hopping between multiple agents, chewing on ideas, and running in the background during meetings, and you're not in on that action, then naturally you're just going to fall behind.

don't be the person on the left side of the cliff.
The tech industry's conveyor belt continues to move forward. If you're a DevOps engineer in 2025 and you don't have any experience with AWS or GCP, then you're going to find it pretty tough in the employment market.
What's surprising to software and data engineers is just how fast this is elapsing. It has been eight months since the release of the first coding agent, and most people are still unaware of how straightforward it is to build one, how powerful this loop is, and its disruptive implications for our profession.
So, my name's Geoffrey Huntley. I was the tech lead for developer productivity at Canva, but as of a couple of months ago, I'm one of the engineers at Sourcegraph building Amp. It's a small core team of about six people. We build AI with AI.






Cursor, Windsurf, Claude Code, GitHub Copilot, and Amp are just a small number of lines of code running in a loop of LLM tokens. I can't stress that enough. The model does all the heavy lifting here, folks. It's the model that does it all.
You are probably five vendors deep in product evaluation, right now, trying to compare all these agents to one another. But really, you're just chasing your tail.
It's so easy to build your own...

There are just a few key concepts you need to be aware of.

Not all LLMs are agentic.
The same way that you have different types of cars, like you've got a 40 series if you want to go off-road, and then you've also got people movers, which exist for transporting people.
The same principle applies to LLMs, and I've been able to map their behaviours into a quadrant.
A model is either high safety, low safety, an oracle, or agentic. It's never both or all.
If I were to ask you to do some security research, which model would you use?
That'd be Grok. That's a low safety model.

If you want something that's "ethics-aligned", it's Anthropic or OpenAI. So that's high safety. Similarly, you have oracles. Oracles are on the polar opposite of agentic. Oracles are suitable for summarisation tasks or require a high level of thinking.
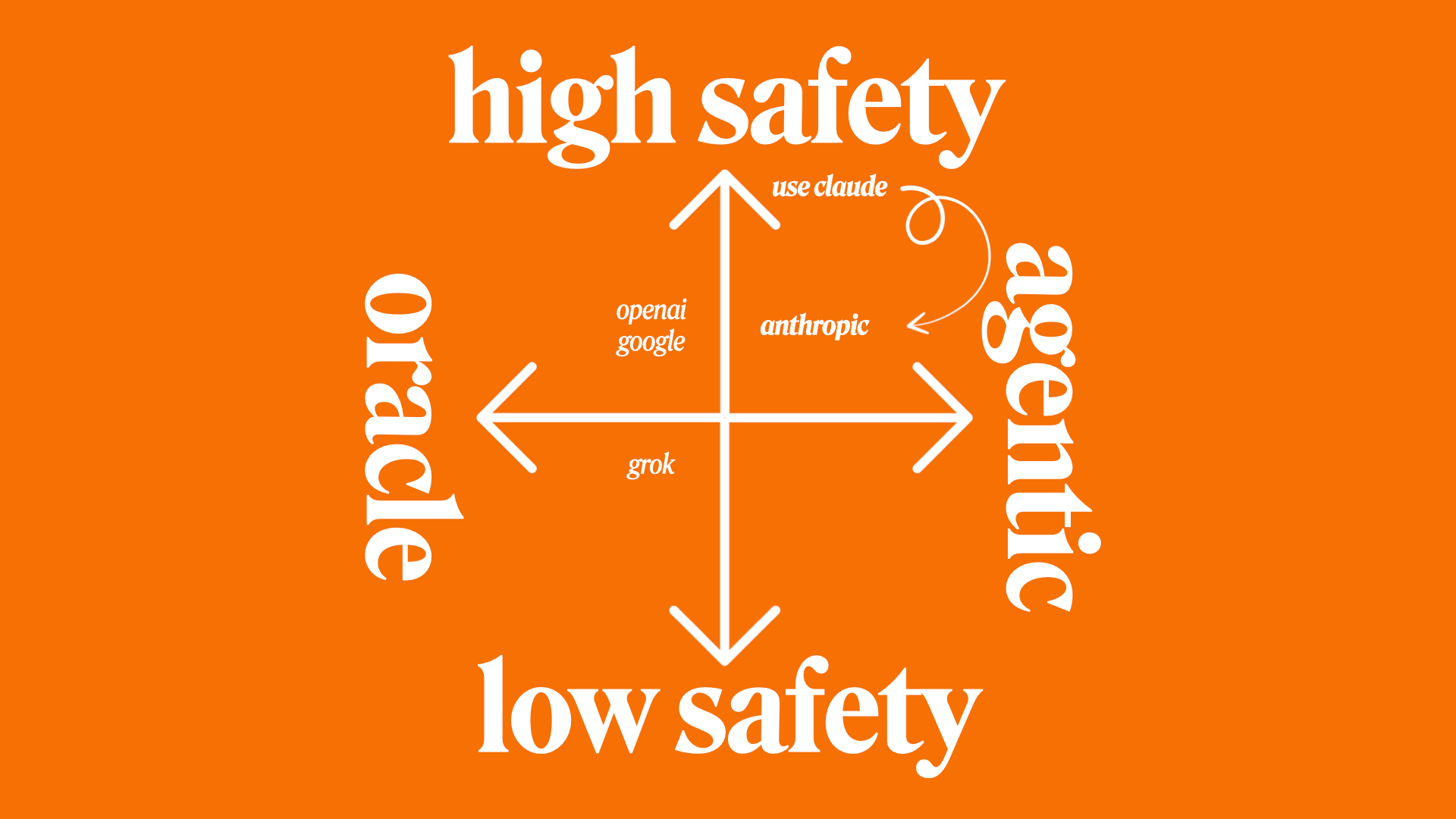
Meanwhile, you have providers like Anthropic, and their Claude Sonnet is a digital squirrel (see below).

The first robot used to chase tennis balls. The first digital robot chases tool calls.
Sonnet is a robotic squirrel that just wants to do tool calls. It doesn't spend too much time thinking; it biases towards action, which is what makes it agentic. Sonnet focuses on incrementally obtaining success instead of pondering for minutes per turn before taking action.
It seems like every day, a new model is introduced to the market, and they're all competing with one another. But truth be told, they have their specialisations and have carved out their niches.
The problem is that, unless you're working with these models at an intimate level, you may not have this level of awareness of the specialisations of the models, which results in consumers just comparing the models on two basic primitives:
- The size of the context window
- The cost
It's kind of like looking at a car, whether it has two doors or three doors, whilst ignoring the fact that some vehicles are designed for off-roading, while others are designed for passenger transport.
To build an agent, the first step is to choose a highly agentic model. That is currently Claude Sonnet, or Kimi K2.
Now, you might be wondering, "What if you want a higher level of reasoning and checking of work that the incremental squirrel does?". Ah, that's simple. You can wire other LLMs in as tools into an existing agentic LLM. This is what we do at Amp.
We call it the Oracle. The Oracle is just GPT wired in as a tool that Claude Sonnet can function call for guidance, to check work progress, and to conduct research/planning.

Amp's oracle is just another LLM registered in as a tool to an agentic LLM that it can function call

The next important thing to learn is that you should only use the context window for one activity. When you're using Cursor or any one of these tools, it's essential to clear the context window after each activity (see below).

LLM outcomtes are a needle in a haystack of what you've allocated into the haystack.
If you start an AI-assisted session to build a backend API controller, then reuse that session to research facts about meerkats. Then it should be no surprise when you tell it to redesign the website in the active session; the website might end up with facts about your API or meerkats, or both.

Context windows are very, very small. It's best to think of them as a Commodore 64, and as such, you should be treating it as a computer with a limited amount of memory. The more you allocate, the worse your outcome and performance will be.
The advertised context window for Sonnet is 200k. However, you don't get to use all of that because the model needs to allocate memory for the system-level prompt. Then the harness (Cursor, Windsurf, Claude Code, Amp) also needs to allocate some additional memory, which means you end up with approximately 176k tokens usable.
You probably heard a lot about the Model Context Protocols (MCPs). They are the current hot thing, and the easiest way to think about them is as a function with a description allocated to the context window that tells it how to invoke that function.
A common failure scenario I observe is people installing an excessive number of MCP servers or failing to consider the number of tools exposed by a single MCP tool or the aggregate context window allocation of all tools.
There is a cardinal rule that is not as well understood as it should be. The more you allocate to a context window, the worse the performance of the context window will be, and your outcomes will deteriorate.
Avoid excessively allocating to the context window with your agent or through MCP tool consumption. It's very easy to fall into a trap of allocating an additional 76K of tokens just for MCP tools, which means you only have 100K usable.
Less is more, folks. Less is more.
I recommend dropping by and reading the blog post below if you want to understand when to use MCP and when not to.

When you should use MCP, when you should not use MCP, and how allocations work in the context window.

Let's head back and check on our agent that's being built in the background. If you look at it closely enough, you can see the loop and how it's invoking other tools.
Essentially, how this all works is outlined in the loop below.
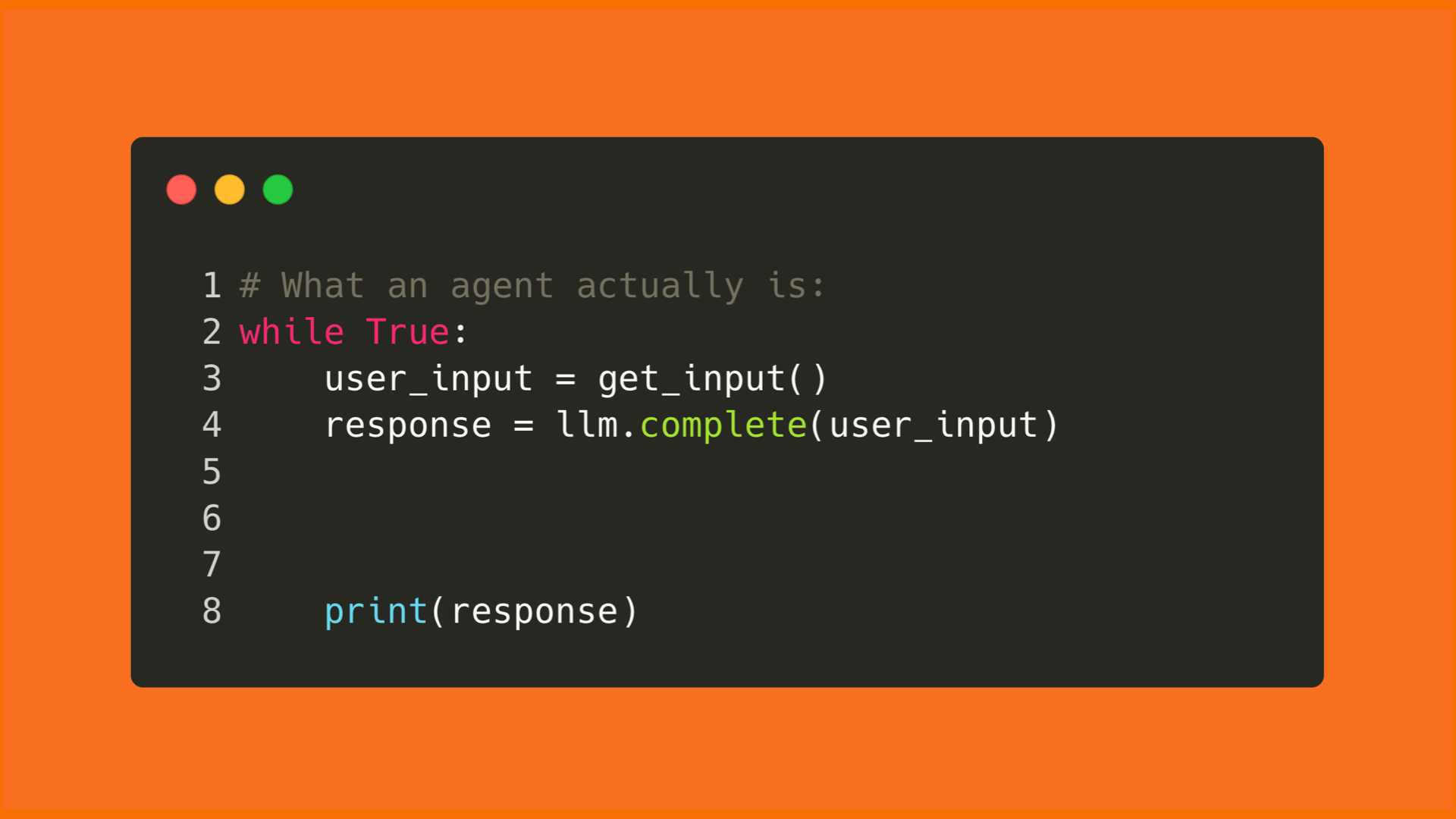
For every piece of input from the user or result of a tool call that gets allocated to the response, and that response is sent off for inferencing:

Let's open up our workshop materials (below) and run the basic chat application via:



